[responsivevoice_button voice=”UK English Female” buttontext=”Listen to Post”]
At BBLTranslation, our expertise goes beyond professional translation and localisation services. We also offer performance audits of AI-powered search engine chatbots, helping clients navigate a rapidly evolving digital landscape. As generative artificial intelligence (AI) becomes integrated into mainstream search platforms, a growing concern is how these tools behave across different languages and cultural contexts.
A recent peer-reviewed study by Kuai et al. (2025) sheds light on this pressing issue. Investigating Microsoft’s Copilot (formerly Bing Chat), the research assessed how the chatbot retrieved political information during the 2024 Taiwan presidential election in five languages. The findings? Significant inconsistencies in factual accuracy, source attribution, and normative behaviour depending on the language used. This has serious implications for AI accountability—and for organisations like ours that prioritise linguistic and cultural equity.
The probabilistic nature of LLMs: not as smart as they seem
Large language models (LLMs), like GPT-4, are statistical machines. As researchers Bender et al. (2021) famously put it, they are “stochastic parrots”—generating outputs based on patterns in the data they were trained on, rather than any real understanding or reasoning. This probabilistic design introduces inherent limitations: misinformation, bias, and the privileging of dominant or hegemonic worldviews.
In short: LLMs are not neutral. They reflect the cultures, languages, and ideologies that shaped their training data. For example, Zhou and Zhang (2023) found that GPT models provided more pro-China responses in Simplified Chinese than in English. Similarly, AI Forensics (2024) highlighted moderation inconsistencies across languages during the EU elections. These findings expose how language choice can dramatically alter chatbot responses, even when the underlying question remains the same.
At BBLTranslation, we’ve seen this firsthand. Our chatbot audits often reveal how translated queries yield different answers—not just in tone or structure, but in factual substance. For clients operating internationally, these variations can undermine trust and transparency.
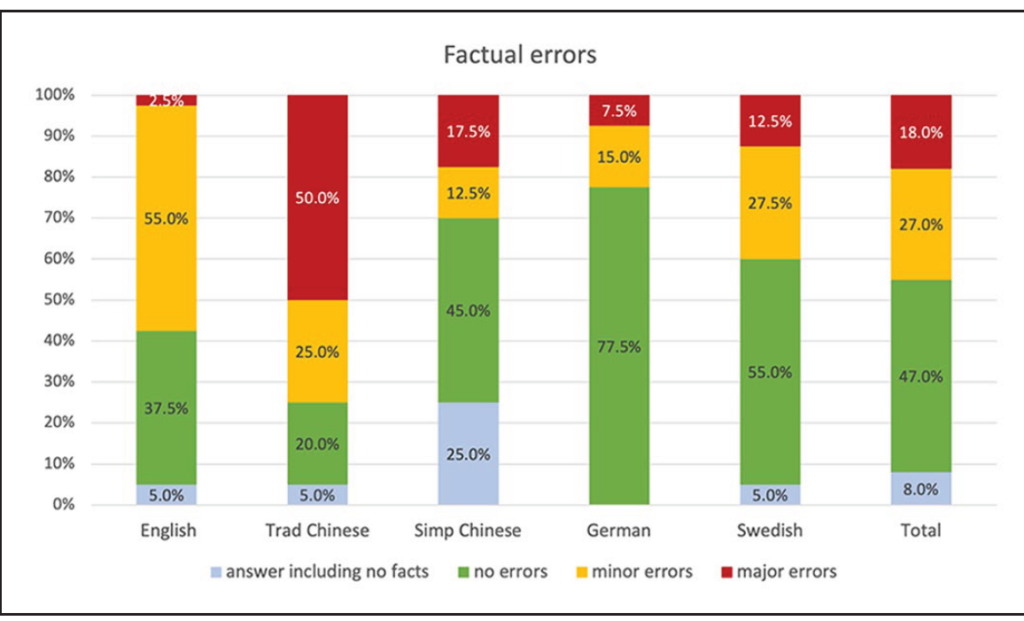
The Kuai et al. (2025) study explored how Copilot responded to the same political prompts in English, Traditional Chinese, Simplified Chinese, German, and Swedish. The results were eye-opening:
- English queries yielded the most consistent and detailed answers.
- Traditional Chinese responses were most prone to factual inaccuracies and often avoided answering political questions.
- German responses were factually accurate but demonstrated bias through omission, such as failing to mention all electoral candidates.
- Swedish prompts saw less outright bias but showed variability in source accuracy and completeness.
These findings speak to a central question in the field: Are AI systems truly consistent across linguistic and cultural divides? The answer, clearly, is no.
This reinforces the need for professional oversight. At BBLTranslation, we conduct multilingual audits of AI-generated content to assess its factual accuracy, neutrality, and adherence to democratic norms—especially when information is politically sensitive or legally regulated.
Transparency isn’t always accountability
While many AI chatbots offer hyperlinks, citations, and references, this appearance of transparency can be deceptive. The Kuai study found that only 63% of the linked content was both accurate and correctly attributed. Some sources were misrepresented, while others were linked incorrectly or even broken.
This level of inaccuracy would be unacceptable in journalism or academia—yet it is quietly tolerated in AI search engines. At BBLTranslation, we call this performative transparency. Our audits investigate not just whether sources are cited, but whether those citations are meaningful, accurate, and contextually appropriate across languages.
Cultural context and legal sensitivities
Language-specific discrepancies often stem from deeper cultural and regulatory differences. In Simplified Chinese, for instance, the chatbot declined to provide polling data, citing a Taiwanese law that prohibits such publication close to an election. The same caution was not applied in other languages.
This shows how AI behaviour can be localised not just linguistically, but ideologically—shaped by assumptions about law, culture, and audience. Without thorough multilingual audits, organisations may unknowingly publish AI-generated content that is misleading, biased, or even non-compliant with regional regulations.
Our role: bridging the gap between language and logic
The study concludes that LLM-powered chatbots are not yet reliable tools for sourcing political information, especially in high-stakes scenarios like elections. At BBLTranslation, we agree—and that’s why we’ve expanded our services to help clients audit, localise, and validate AI-generated outputs across languages.
We don’t just translate; we interrogate the information flow. We analyse whether AI responses:
- Contain factual errors or misrepresentations.
- Are consistent across languages and cultural contexts.
- Provide legitimate, verifiable sources.
- Align with your organisation’s values and regulatory responsibilities.
Final thoughts: multilingual accountability is non-negotiable
Generative AI will only become more integrated into the platforms we use every day. But as this study demonstrates, its performance across languages remains erratic and, at times, ethically questionable. If LLMs are to serve the public good, they must be held to account—not just in English, but in every language they claim to understand.
At BBLTranslation, we stand at the intersection of language, technology, and ethics. Through rigorous audits and linguistic insight, we help clients harness the potential of AI—while safeguarding against its pitfalls.
Learn more about our AI chatbot auditing services
Would you like a personalised analysis of your AI chatbot’s responses in multiple languages? Reach out for an expert language audit!
Source: Kuai, J., Brantner, C., Karlsson, M., Van Couvering, E., & Romano, S. (2025). AI chatbot accountability in the age of algorithmic gatekeeping: Comparing generative search engine political information retrieval across five languages. New Media & Society, 14614448251321162.
Photo courtesy of Gerd Altmann from Pixabay


